Statistical Significance Abuse
A lot of research makes scientific evidence seem much more “significant” than it is

an excerpt from xkcd, geeky web comic
This article is about two common problems with “statistical significance” in medical research. Both problems are particularly rampant in the study of massage therapy, chiropractic, and alternative medicine in general, and are wonderful examples of why science is hard, “why most published research findings are false”1 and genuine robust treatment effects are rare:2
- mixing up statistical and clinical significance and the probability of being “right”
- reporting statistical significance of the wrong dang thing
Stats are hard and scary, of course — everyone knows that. But there will be comic strips, funny videos, and diagrams. I’ll try to make it worth your while, and I’ll try to simplify dramatically without butchering underlying math. Angels fear to tread here!
Significance Problem #1
Two flavours of “significant”: statistical versus clinical
Research can be statistically significant, but otherwise unimportant. Statistical significance means that data signifies something… not that it actually matters.
Statistical significance on its own is the sound of one hand clapping. But researchers often focus on the positive: “Hey, we’ve got statistical significance! Maybe!” So they summarize their findings as “significant” without telling us the size of the effect they observed, which is a little devious or sloppy. Almost everyone is fooled by this — except 98% of statisticians — because the word “significant” carries so much weight. It really sounds like a big deal, like good news.
But it’s like bragging about winning a lottery without mentioning that you only won $25.3
Statistical significance without other information really doesn’t mean all that much. It is not only possible but common to have clinically trivial results that are nonetheless statistically significant. How much is that statistical significance worth? It depends … on details that are routinely omitted.
Which is convenient if you’re pushing a pet theory, isn’t it?
Imagine a study of a treatment for pain, which has a statistically significant effect, but it’s a tiny effect: that is, it only reduces pain slightly. You can take that result to the bank (supposedly) — it’s real! It’s statistically significant! But … no more so than a series of coin flips that yields enough heads in a row to raise your eyebrows. And the effect was still tiny. So calling these results “significant” is using math to put lipstick on a pig.
There are a lot of decorated pigs in research: “significant” results that are possibly not even that, and clinically boring in any case.
Just because a published paper presents a statistically significant result does not mean it necessarily has a biologically meaningful effect.
Science Left Behind: Feel-Good Fallacies and the Rise of the Anti-Scientific Left, Alex Berezow & Hank Campbell
If you torture data for long enough, it will confess to anything.
Ronald Harry Coase
P-values, where P stands for “please stop the madness”
Statistical significance is boiled down to one convenient number: the infamous, cryptic, bizarro and highly over-rated P-value. Cue Darth vader theme. This number is “diabolically difficult” to understand and explain, and so p-value illiteracy and bloopers are epidemic (Goodman identifies ““A dirty dozen: twelve p-value misconceptions””4). It seems to be hated by almost everyone who actually understands it, because almost no one else does. Many believe it to be a blight on modern science.5 Including the American Statistical Association6 — and if they don’t like it, should you? In 2019, they strongly recommended that everyone just please stop saying “statistically significant” altogether:7
The ASA Statement on P-Values and Statistical Significance stopped just short of recommending that declarations of “statistical significance” be abandoned. We take that step here. We conclude, based on our review of the articles in this special issue and the broader literature, that it is time to stop using the term “statistically significant” entirely. Nor should variants such as “significantly different,” “p < 0.05,” and “nonsignificant” survive, whether expressed in words, by asterisks in a table, or in some other way.
Regardless of whether it was ever useful, a declaration of “statistical significance” has today become meaningless.
The mathematical soul of the p-value is, frankly, not really worth knowing. It’s just not that good an idea, and it never was. The importance of scientific research results cannot be jammed into a single number (and nor was that ever the intent). And so really wrapping your head around it is no more important than learning the gritty details of the Rotten Tomatoes algorithm when you’re trying to decide whether to bother with a movie.8
What you do need to know is the role that p-values play in research today. You need to know that “it depends” is a massive understatement, and that there are “several reasons why the p-value is an unobjective and inadequate measure of evidence”9
Above all, a good p-value is not a low chance that the results were a fluke or false alarm — which is by far the most common misinterpretation (and the first of Goodman’s Dirty Dozen). The real definition is a kind of mirror image of that:12 it’s not a low chance of a false alarm, but a low chance of an effect that actually is a false alarm. The false alarm is a given! That part of the equation is already filled in, the premise of every p-value. For better or worse, the p-value is the answer to this question: if there really is nothing going on here, what are the odds of getting these results? A low number is encouraging, but it doesn’t say the results aren’t a fluke, because it can’t13 — it was calculated by assuming they are.
The only way to actually find out if the effect is real or a fluke is to do more experiments. If they all produce results that would be unlikely if there was no real effect, then you can say the results are probably real. The p-value alone can only be a reason to check again — not statistical congratulations on a job well done. And yet that’s exactly how most researchers use it. And most science journalists.14
Head hurting already? Time for the stick people to take over this tutorial.
Learn research statistics from stick people!
Geeky web comic xkcd illustrated the trouble with statistical significance better than I can with my paltry words.

Hard-hitting comic analysis
A “5% chance of coincidence” is actually a fairly strong chance of a coincidence. That’s one in twenty. That can happen. Something with a one in twenty chance of happening each day is going to happen more than once per month.

Roll a 20-sided die (that’s a Dungeons & Dragons thing) and you’ll notice that any given number comes up pretty often!
Randall Munroe hides an extra little joke in all his comic strips (mouse over his comic strips on his website, wait a moment, and they are revealed). This time it was:
'So, uh, we did the green study again and got no link. It was probably a--' 'RESEARCH CONFLICTED ON GREEN JELLY BEAN/ACNE LINK; MORE STUDY RECOMMENDED!'
A great deal of crap science is presented in exactly this way. It’s one of the main ways that “studies show” a lot of things help pain that actually do no such thing. It’s one of the easiest ways for the “controversy” over many alternative treatments can be sustained, rather than just moving the heck on: by citing “significant” evidence of benefit, with data exactly as absurd as in the comic strip above.
It’s actually statistically typical for studies to make bad treatments look good. It happens regularly.
Statistics are like bikinis: what they reveal is suggestive, but what they conceal is vital.
Aaron Levenstein
A general example of significance problem #1: chiropractic spinal adjustment
A classic real world example of “statistically significant but clinically trivial” is the supposedly proven benefit of chiropractic adjustment: how much benefit, exactly? “Less than the threshold for what is clinically worthwhile,” as it turns out, according to Nefyn Williams, author of a 2011 paper in International Musculoskeletal Medicine.15 I have been pointing out that spinal adjustment benefits seem to be real-but-minor for many years now, and I explore that evidence in crazy detail in my low back pain and neck pain tutorials. It’s a big topic, with lots of complexity.
Williams’ paper offers an oblique perspective that is quite different and noteworthy: his paper is not about chiropractic adjustment, but about the concept of clinical significance itself. There are various ways of measuring improvement in scientific tests of treatments, and, as Williams explains, “when an outcome measure improves by, say, five points it is not immediately apparent what this means.” How much improvement matters? After explaining and discussing various proposed standards and methods, Williams needed a good example to make his point. It’s quite interesting that he picked spinal manipulative therapy.

A specific example of significance problem #1: chondroitin sulfate
Chondroitin sulfate is a “nutraceutical” — a food-like nutritional supplement that is supposedly “good for cartilage” (because it is a major component of cartilage). It has been heavily studied, but there has never been any clear good scientific news about it, and it bombed a particularly large and good quality test in 2006 (see Clegg).
So it was a bit hard to believe my eyes when I read the summary of a 2011 experiment claiming that chondroitin sulfate “improves hand pain.”16 Really?!
No, not really. On a 100mm VAS (a pain scale, “visual analogue scale”), the treatment group was 8.77mm happier with their hands. With a p=.02 (a middlin’ p-value, neither high nor low). So basically what the researchers found is a chance that chondroitin makes a small difference in arthritis pain. It’s not nothing, but it is an incredibly unimpressive result — pretty much the definition of clinically insignificant. The authors’ interpretation is like taking the dog to the end of the driveway and saying you took him for a walk. Technically true ...
So that is a lovely demonstration of the abuse of statistical significance!
Significance Problem #2
Statistical significance of the wrong comparison (no analysis of variance, or the “difference of differences”)
Problem #1 with significance is more like a lie than an error.17 The second one is definitely an error — something that would get you a failing grade in a basic statistics course.
This bomb comes from an analysis of neuroscience research.18 It was described by Ben Goldacre for The Guardian as
a stark statistical error so widespread it appears in about half of all the published papers surveyed from the academic neuroscience research literature.
Dr. Steven Novella also wrote about it for ScienceBasedMedicine.org recently, adding that
there is no reason to believe that it is unique to neuroscience research or more common in neuroscience than in other areas of research.
And it is not. Dr. Christopher Moyer is a psychologist who studies massage therapy:
I have been talking about this error for years, and have even published a paper on it. I critiqued a single example of it, and then discussed how the problem was rampant in massage therapy research. Based on the Nieuwenhuis paper, apparently it’s rampant elsewhere as well, and that is really unfortunate. Knowing the difference between a within-group result and a between-groups result is basic stuff.
So what's the error?
A significantly irrelevant significant difference
It’s so basic in a way: it’s just basing the conclusion on how much better a treatment is than nothing at all rather than how much better it is than a placebo, as long as it did better than a placebo. But it has to be significantly better than the placebo — not just better than nothing.20
On its own, a “statistically significant” difference between treatment and nothing at all is the sound of one hand clapping. A informative comparison has to be a statistical ménage à trois, comparing all three to each other. Or four, or seven. There are a lot of differences to compare in some research! This is often summarized as comparing the “difference in differences,” technically known as an analysis of variance, or ANOVA. Every good clinical trial must do this.
And, shockingly, Nieuwenhuis et al. reported that more than half of neuroscience researchers were not doing this. And I assure you it’s worse in the world of pain and injury medicine!
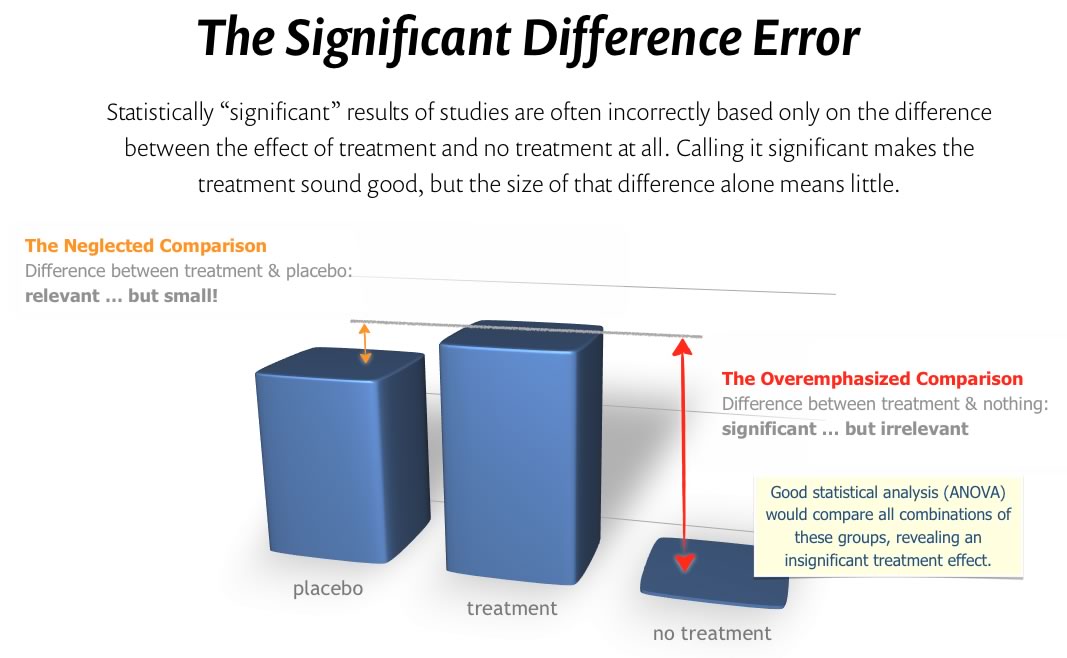
Massage is better than nothing! Too much better …
Studies of massage therapy (and others, like chiropractic21) are particularly plagued by this error. Why? Because massage is so much “better than nothing.” The size of that difference looms large, and so it’s all too easy to mistake it for the one that matters — and fail to even compare the treatment to a placebo. And it’s really hard to come up with a meaningful placebo. It’s notoriously difficult to give a patient a fake massage. (They catch on.)
Statistics does not care about these difficulties: you still can’t compare massage to nothing, stop there, and call the difference “significant.” You still have to do your ANOVA, and massage still has to beat some kind of placebo before it can be considered more effective than pleasant grooming.
This research problem is not limited to massage, but massage is one of best examples of it. This crops up when you’re studying any treatment that involves a lot of interaction. The more interaction, the worse the problem gets. It’s a big deal in massage research because massage involves a lot of interaction, much of which is pleasant and emotionally engaging.
Much of the good done by therapists of all kinds is attributable to potent placebos driven by their complex interactions with patients, and not by anything in particular that they are doing to the patient. To find out how well a therapy works, it must be compared to sham treatments which are as much like the treatment as possible. This is hard to do, and it has rarely been done well. It’s much more typical to compare therapy to something too lifeless and “easy to beat,” to much like comparing it to nothing at all instead of a real placebo. And there’s the difference error: comparison to the wrong thing, statistical significance of the wrong difference.
The Touch Research Institute: a history of statistical significance errors
The Touch Research Institute was, for many years, a small Florida organization devoted to proving that touch and massage are effective medicine — a powerful bias baked into their mission. Any massage therapist with even the slightest interest in massage research has heard of TRI and their studies (but few have heard of any other massage research). TRI produced hundreds of massage-boosting studies over the years. And that should ring an alarm — researchers that always get the same predictable answer are probably doing something wrong. The goal of science is not to prove what we think we already know, but to find out how things actually are.
TRI produced many studies corrupted by the within-group significance fallacy. Indeed, it can be found in most of them — their entire body of work is rotten with this seductive, self-serving statistical mistake. The error is probably the primary mechanism of TRI’s uniformly positive results. It’s a superb case study of how a bias can wreck research. I learned to stop taking their results seriously quite early in my career, by the late 2000s at the latest.
Did you find this article useful? Interesting? Maybe notice how there’s not much content like this on the Internet? That’s because it’s crazy hard to make it pay. Please support (very) independent science journalism with a donation. See the donation page for more information & options.
About Paul Ingraham

I am a science writer in Vancouver, Canada. I was a Registered Massage Therapist for a decade and the assistant editor of ScienceBasedMedicine.org for several years. I’ve had many injuries as a runner and ultimate player, and I’ve been a chronic pain patient myself since 2015. Full bio. See you on Facebook or Twitter., or subscribe:
Related Reading
- Most Pain Treatments Damned With Faint Praise — Most controversial and alternative therapies are fighting over scraps of “positive” scientific evidence that damn them with the faint praise of small effect sizes that cannot impress
- Science versus Experience in Physical Medicine — The conflict between science and clinical experience and pragmatism in the management of aches, pains, and injuries
- Why “Science”-Based Instead of “Evidence”-Based? — The rationale for making medicine based more on science and not just evidence… which is kinda weird
- Ioannidis: Making Medical Science Look Bad Since 2005 — A famous and excellent scientific paper … with an alarmingly misleading title
- Why “Science”-Based Instead of “Evidence”-Based? — The rationale for making medicine based more on science and not just evidence… which is kinda weird
- Alternative Medicine’s Choice — What should alternative medicine be the alternative to? The alternative to cold and impersonal medicine? Or the alternative to science and reason?
- Statistical Significance Abuse — A lot of research makes scientific evidence seem much more “significant” than it is
- The Power of Barking: Correlation, causation, and how we decide what treatments work — A silly metaphor for a serious point about the confounding power of coincidental and inevitable healing, and why we struggle to interpret our own recovery experiences
- Statistics Done Wrong: The Woefully Complete Guide (statisticsdonewrong.com). The free online version of the excellent book Statistics Done Wrong, by Alex Reinhart.
What’s new in this article?
Sep 18, 2025 — Some clarifications, additional detail, and minor corrections on the topic of the within-group significance fallacy.
2020 — Updated the American Statistical Association’s new position on completely avoiding the use of “statistically significant.”
2016 — Science update: citation to Pereira 2012 about the lack of large treatment effects in medicine.
2011 — Publication.
Notes
- Ioannidis J. Why Most Published Research Findings Are False. PLoS Medicine. 2005 08;2(8):e124. PainSci Bibliography 55463 ❐
This intensely intellectual paper — it’s hopelessly nerdy — became one of the most downloaded articles in the history of the Public Library of Science and was described by the Boston Globe as an instant classic. Despite the title, the paper does not, in fact, say that “science is wrong,” but something much less sinister: that it should take rather a lot of good quality and convergent scientific evidence before we can be reasonably sure of something, and he presents good evidence that a lot of so-called conclusions are premature, not as “ready for prime time” as we would hope. This is not the least bit surprising to good scientists, who never claimed in the first place that their results are infallible or that their conclusions are “true.”
I go into much more detail here: Ioannidis: Making Medical Science Look Bad Since 2005.
- Pereira TV, Horwitz RI, Ioannidis JPA. Empirical evaluation of very large treatment effects of medical interventions. JAMA. 2012 Oct;308(16):1676–84. PubMed 23093165 ❐
A “very large effect” in medical research is probably exaggerated, according to Stanford researchers. Small trials of medical treatments often produce results that seem impressive. However, when more and better trials are performed, the results are usually much less promising. In fact, “most medical interventions have modest effects” and “well-validated large effects are uncommon.”
Let’s spell that out a bit: a friend approaches you, and excitedly reports that he had won some money — but rather than telling you how much, he brags only about the odds: “It was a twenty to one!” he says happily, and goes for a high five. You indulge him with a high five, and then demand to know how much he actual won.
“Um, three dollars. But I won!”
This is how silly it is to declare statistical significance without clear reference to effect size.
- Goodman S. A dirty dozen: twelve p-value misconceptions. Semin Hematol. 2008 Jul;45(3):135–40. PubMed 18582619 ❐
- Nuzzo R. Scientific method: statistical errors. Nature. 2014 Feb;506(7487):150–2. PubMed 24522584 ❐
P values have always had critics. In their almost nine decades of existence, they have been likened to mosquitoes (annoying and impossible to swat away), the emperor’s new clothes (fraught with obvious problems that everyone ignores) and the tool of a “sterile intellectual rake” who ravishes science but leaves it with no progeny. One researcher suggested rechristening the methodology “statistical hypothesis inference testing”, presumably for the acronym it would yield.
- www.nature.com [Internet]. Baker M. Statisticians issue warning over misuse of P values; 2016 March 8 [cited 22 May 17]. PainSci Bibliography 53432 ❐
Misuse of the P value — a common test for judging the strength of scientific evidence — is contributing to the number of research findings that cannot be reproduced, the American Statistical Association (ASA) warns in a statement released today. The group has taken the unusual step of issuing principles to guide use of the P value, which it says cannot determine whether a hypothesis is true or whether results are important.
- Ronald L. Wasserstein, Allen L. Schirm, Nicole A. Lazar. Moving to a World Beyond “p<0.05”. The American Statistician. 2019;73(sup1):1–19. PainSci Bibliography 52278 ❐
ABSTRACT
Some of you exploring this special issue of The American Statistician might be wondering if it’s a scolding from pedantic statisticians lecturing you about what not to do with p-values, without offering any real ideas of what to do about the very hard problem of separating signal from noise in data and making decisions under uncertainty. Fear not. In this issue, thanks to 43 innovative and thought-provoking papers from forward-looking statisticians, help is on the way.
- First, just don’t. It’s terrible. It’s not a gritty new “vision” of Godzilla: it’s a stilted and stale-on-arrival stinker that doesn’t even satisfy with the effects, let alone script, and how in hell did an actor of Brian Cranston’s calibre end up in there? The good reviews and the decent Tomatometer score of ~70% are really a puzzle. Second, the Tomatometer is an amusingly apt analogy for the p-value problem: an algorithm that produces a simple score that is routinely misinterpreted and fundamentally incapable of telling us what we really want to know, while seemed to promise exactly that. It’s even been analyzed in the same exasperated way! See Misinterpreting the Tomatometer, which concludes, “The Tomatometer is a reliable way of measuring Tomatometer ratings. That’s about it.” Similarly, p-values seem to be, above all, an excellent indication of the p-value and not super reliable for anything else.
- Hubbard R, Lindsay RM. Why P Values Are Not a Useful Measure of Evidence in Statistical Significance Testing. Theory & Psychology. 2008;18(1):69–88. PainSci Bibliography 53786 ❐
ABSTRACT
Reporting p values from statistical significance tests is common in psychology's empirical literature. Sir Ronald Fisher saw the p value as playing a useful role in knowledge development by acting as an "objective" measure of inductive evidence against the null hypothesis. We review several reasons why the p value is an unobjective and inadequate measure of evidence when statistically testing hypotheses. A common theme throughout many of these reasons is that p values exaggerate the evidence against H0. This, in turn, calls into question the validity of much published work based on comparatively small, including .05, p values. Indeed, if researchers were fully informed about the limitations of the p value as a measure of evidence, this inferential index could not possibly enjoy its ongoing ubiquity. Replication with extension research focusing on sample statistics, effect sizes, and their confidence intervals is a better vehicle for reliable knowledge development than using p values. Fisher would also have agreed with the need for replication research.
- Regina Nuzzo (again): “The more implausible the hypothesis — telepathy, aliens, homeopathy — the greater the chance that an exciting finding is a false alarm, no matter what the P value is.” And yet studies of implausible treatments is exactly where p-values are typically emphasized by researchers with an agenda.
- Pandolfi M, Carreras G. The faulty statistics of complementary alternative medicine (CAM). Eur J Intern Med. 2014 Sep;25(7):607–9. PubMed 24954813 ❐
ABSTRACT
The authors illustrate the difficulties involved in obtaining a valid statistical significance in clinical studies especially when the prior probability of the hypothesis under scrutiny is low. Since the prior probability of a research hypothesis is directly related to its scientific plausibility, the commonly used frequentist statistics, which does not take into account this probability, is particularly unsuitable for studies exploring matters in various degree disconnected from science such as complementary alternative medicine (CAM) interventions. Any statistical significance obtained in this field should be considered with great caution and may be better applied to more plausible hypotheses (like placebo effect) than that examined - which usually is the specific efficacy of the intervention. Since achieving meaningful statistical significance is an essential step in the validation of medical interventions, CAM practices, producing only outcomes inherently resistant to statistical validation, appear not to belong to modern evidence-based medicine.
Like a German word with no exact English translation, there really is no way to properly define p-value without some jargon. (Or at least that’s how I justify my own past erroneous definitions.) So here’s a proper definition now, including the essential jargon — specifically the “null hypothesis” — here’s Goodman’s definition: “The probability of the observed result, plus more extreme results, if the null hypothesis were true.”
The null hypothesis is basically the bet there’s actually no effect for the experiment to find. If that bet is right, then you’re only going observe the appearance of an effect due to a fluke or error. The null hypothesis is difficult but really interesting idea, and I cover it in some detail in Why So “Negative”? Answering accusations of negativity, and my reasons and methods for debunking bad treatment options for pain and injury.
- Sellke T, Bayarri MJ, Berger JO. Calibration of ρ Values for Testing Precise Null Hypotheses. The American Statistician. 2001;55(1):62–71. PainSci Bibliography 53787 ❐
ABSTRACT
P values are the most commonly used tool to measure evidence against a hypothesis or hypothesized model. Unfortunately, they are often incorrectly viewed as an error probability for rejection of the hypothesis or, even worse, as the posterior probability that the hypothesis is true. The fact that these interpretations can be completely misleading when testing precise hypotheses is first reviewed, through consideration of two revealing simulations. Then two calibrations of a ρ value are developed, the first being interpretable as odds and the second as either a (conditional) frequentist error probability or as the posterior probability of the hypothesis.
- Including myself for years — mea culpa.
- Williams NH. How important is the ‘minimal clinically important change’? International Musculoskeletal Medicine. 2011 Jun;33(2):47–82(2). PainSci Bibliography 55101 ❐
- Gabay C, Medinger-Sadowski C, Gascon D, Kolo F, Finckh A. Symptomatic effects of chondroitin 4 and chondroitin 6 sulfate on hand osteoarthritis: a randomized, double-blind, placebo-controlled clinical trial at a single center. Arthritis Rheum. 2011 Sep 6;63(9). PubMed 21898340 ❐
- Or a lie of omission, or bending of the truth, a bit of rhetorical sleight of hand. It works well and fools a lot of people — sometimes, I think, even the scientists or doctors who are using it. The usage of the term “significant” is often technically correct, but obscures and diverts attention away from the whole story.
- Nieuwenhuis S, Forstmann BU, Wagenmakers EJ. Erroneous analyses of interactions in neuroscience: a problem of significance. Nat Neurosci. 2011;14(9):1105–7. PubMed 21878926 ❐ PainSci Bibliography 55075 ❐
- And, of course, there’s good overlap between those things. What people “know” is partly a function of what we want to know…and what we want to avoid learning. We all do it. In a unconscious and non-malicious way, we conveniently fail to learn things that don’t confirm our biases. Oopsie! This is, of course, why “it’s hard to get someone to understand something when their job depends on not understanding it.”
Clinical trials are all about comparing treatments. To be considered effective, a real treatment has to work better than a fake one — a placebo. A drug must produce better results than a sugar pill. If that difference is big enough, only then is the good news “statistically significant.” There are a lot of details, but that’s the beating heart of a fair scientific test: can the treatment beat a fake to a meaningful degree?
What you can’t do is just compare the treatment to nothing at all and say, “See, it works: huge difference! Huge improvement over nothing!” The problem is that both genuinely effective medicines and placebos can easily beat nothing — it just doesn’t mean much until you know the treatment can also trounce a placebo.
- This is a problem studying any kind of therapy where patients spend more time with health care professionals. The more time and interaction, the worse the problem. Thus, massage is by far the most difficult of them all — but it’s also a problem studying chiropractic, physical therapy, psychotherapy, osteopathy, and so on. Basically, the higher the potential for a robust placebo, the harder it gets to avoid making this research mistake.